| из песни ... не выкинешь |
Пояснительная записка
| Поэтическая речь представляет собой структуру большой сложности. Она значительно усложнена по отношению к естественному языку. И если бы объем информации, содержащийся в поэтической (стихотворной или прозаической -- в данном случае не имеет значения) и обычной речи, был одинаковым, художественная речь потеряла бы право на существование и, бесспорно, отмерла бы. | |
| Юрий Лотман, "Лекции по структуральной поэтике", II.3 | |
|
-- Это я и сам знаю, -- вздохнул разочарованный удав. -- А какой
длинный? -- Очень длинный. -- Очень? -- удав задумался. -- Хм, очень... Нет. Очень -- это не то! | |
| Григорий Остер, "Это я ползу" ("38 попугаев") |
Работа Юрия Лотмана, из которой взят первый эпиграф, написана в 64-м. Физики и лирики, может ли машина мыслить, понедельник начинается в субботу, Валентина Терешкова, он живой и светится, знание -- сила... С тех пор утекло много воды. На Марс мы так и не полетели. Машина победила чемпиона мира по шахматам, но как-то скучно, без души, задавив грубой силой, как паровой каток. Мечта о Всемирном Информатории обернулась реализацией заросшего паутиной Всемирного Чердака, по которому снуют паукообразные роботы в поисках чего-нибудь полезного. Соединение в одном предложении слов "информация" и "стихотворение" вызывает сейчас нежное ностальгическое чувство. Будем считать, что оно и служит достаточным основанием для нашего предприятия, и вопросом "зачем" задаваться больше не будем.
Заранее приношу извинения профессионалам (филологам и математикам)
за элементарный уровень изложения и неизбежные упущения и
неточности, а также за излишне категоричные
утверждения. Любые дополнения, уточнения и исправления будут с
признательностью приняты и приобщены.
Но покончим с предисловиями. Имя Лотмана неразрывно связано со структурализмом тартуской школы филологии. Пафосом структурализма было превращение филологии в точную науку. Основная идея структурализма в том, что художественный текст -- структура, в которой всякий элемент -- слово, звук, образ, ритмическая фигура и т.д., -- приобретает смысл только в соотнесенности (со- и противопоставленности) с другими элементами. Отношения между элементами приобретают такую жизненную силу, что отсутствие элемента там, где отношения его предполагают, как отсутствие рифмы в рифмованном стихе, сбивка ударения, укороченная строка, -- становится тоже значимым элементом ("минус-прием"). Центр тяжести переносится с рассмотрения элементов, как таковых, на анализ (структурных) взаимоотношений между ними, из которых и возникает содержание. Отделять содержание от формы оказывается так же нелепо, как (пример Лотмана) узнав, что у здания есть план, ломать стены в поисках этого плана.
Метод структурализма оказался чрезвычайно плодотворным, и далеко не
только в стиховедении. Но надежды на тогдашнюю царицу наук --
кибернетику не оправдались, слова о повышенном объеме информации
в стихе так и остались метафорой, точного научного содержания не
имеющей.
Шенноновская информация
Представьте себе, что вы играете в игру "Угадай букву". Какая-нибудь рулетка выкидывает одну из 32 букв русского алфавита, а вы должны ее угадать. Понятно, что если рулетка честная, вы будете угадывать с вероятностью 1/32. Предположим, что вам разрешают, прежде чем угадывать, задать один вопрос на "да и нет". Вы можете повысить вероятность успеха вдвое, если спросите, находится ли буква в первой половине алфавита. Ответ (все равно, утвердительный или отрицательный) снижает количество возможностей до 16. Точно так же, если вам разрешают задать два вопроса, вы можете повысить вероятность попадания еще вдвое, до 1/8. Что здесь происходит? С каждым ответом вы получаете информацию, а именно 1 бит информации. Один бит вдвое уменьшает неопределенность. Отсюда общее определение: количество информации в битах равно двоичному логарифму отношения количества (равновероятных) возможностей до и после получения информации.Количество информации может быть меньше бита. Например совет "пойдешь направо -- коня потеряешь" несет витязю на распутье log2(3/2), т.е. чуть больше пол-бита информации. А когда вы размышляете над меню в ресторане, не зная, что выбрать, и подоспевший официант начинает расписывать сегодняшние особые, отсутствующие в меню блюда, то он, как ни странно, сообщает вам отрицательное количество информации, лишь увеличивая вашу растерянность перед лицом и без того трудного выбора. (Это не так, впрочем, если вы склонны верить официанту и выбирать то, что он посоветует.)
Как, однако, эту теорию приложить к интересующей нас области? Заметим, что чтение -- это приблизительно то же самое, что игра "Угадай букву". Приблизительно -- потому, что нормально мы читаем, конечно, целыми словами и словосочетаниями, а не побуквенно, но эта разница скорее количественная ("Угадай слово"), чем принципиальная. Представьте, что вам выпадают такие буквы: "б", "у", "р", "я", "м", "г", "л", "о"... не сомневаюсь, что следующую букву вы угадаете с вероятностью 1. Случайно такая последовательность выпадает один раз на триллион. Как это вышло? Откуда у вас взялась информация (в количестве 5 бит) о следующей букве? Ясно, откуда: из предыдущих букв. Но если так, то следующая буква уже не несет в себе нисколько информации, она предсказуема.
Этот пример иллюстрирует крайний случай: наперед известный нам текст не несет информации. Здесь теория информации более или менее согласуется с нашей интуицией. Зато в другом крайнем случае выходит конфуз: согласно теории информации, самое большое количество информации содержится в случайном наборе букв (5 бит на каждую совершенно непредсказуемую букву). Мы, пожалуй, согласимся с тем, что повышение неожиданности, непредсказуемости текста повышает его информативность, -- но только до определенного предела, пока он сохраняет смысл. Дальше она (информативность) должна резко падать до нуля, а не продолжать расти, как получается по теории информации.
Интересно еще заметить, что и в давно знакомом тексте, если это хорошее стихотворение или, например, роман, мы раз от раза открываем новые грани и глубины, так что сказать, что он не несет никакой информации, было бы не совсем верно.
Как бы то ни было, эксперименты по измерению информационного
содержания текстов проводились, и именно описанным выше методом
игры в угадайку.
Но зато на методику эксперимента следует обратить внимание. У нее есть по крайней мере два замечательных качества. Во-первых, она проста, легко автоматизируется и дает количественный результат. Во-вторых, она естественно и неотъемлемо включает реципиента информации (читателя) в систему. Мало того, она использует этого читателя, как измерительный прибор. Если мы хотим измерять художественное содержание, без датчика, способного реагировать на это содержание, никак не обойтись, а иных датчиков у нас нет и не скоро будут.
Но вернемся к теории информации: почему она настолько расходится с интуицией? Главным образом потому, что мы попытались ее применить не по назначению. Мы говорим, что каждая следуюшая буква случайной последовательности несет 5 бит информации. Информации о чем? По существу -- только о самой себе. Если последовательность не совсем случайная, то и о следующих буквах. Но и только. Такой подход плодотворен и полезен, когда мы имеем дело, например, с передачей изображений по проводам. В отношении же художественного текста нас интересует "информация", которую он сообщает нам о предметах, внешних по отношению к тексту, -- о мире, об авторе, о нас самих... Лотман: "избыточность на уровне художественного сообщения стремится к нулю, сохраняясь на уровне языкового" (с. 241). То есть, хотя буквы мы можем предсказывать довольно хорошо, но угадать куда повернет образ, все равно не удастся. Ясно, что надеяться напрямую померить числом такую информативность было бы по меньшей мере наивно.
На самом деле, мне кажется даже, что само слово "информативность"
подталкивает нас на тупиковый путь. Попробуйте вспомнить, когда вы в
последний раз, прочитав замечательное стихотворение, подумали
что-нибудь вроде: "Ух ты, как интересно, а я и не знал". То есть,
Узнали Что-то Новое. По-моему, так почти никогда не бывает.
Колмогоровская сложность
Помимо информативности, или содержательности, постоянным атрибутом художественной речи в структуралистских работах выступает сложность. Она трактуется как насыщенность текста разнообразными связями, как внутренними, так и внешними (отсылками к культурным контекстам, например). Опять процитирую все ту же страницу 241 лотмановской классической книги:Информативность поэтического текста зависит от совершенно иного соотношения планов выражения и содержания, чем в языке, от превращения всех элеметов текста в семантически насыщенные, от их взаимной соотнесенности, от того, что поэзия не знает отдельных элементов и все самодовлеющие явления языка становятся в стихотворном тексте взаимно со-противопоставляемыми.Чтобы вполне понять, о чем тут речь, надо читать лотмановские разборы конкретных стихов. Здесь нас, однако, интересует голая идея: информативность -- следствие (структурной) сложности. Интуитивно это не вызывает протеста. Неясно, правда, как формально вывести информативность из сложности, но пока у нас нет формального определения сложности, это вопрос, очевидно, преждевременный. Нет ли у математиков понятия сложности, которым можно было бы воспользоваться?
Есть. Сложность комбинаторного объекта, по Колмогорову, измеряется минимальной длиной программы, которая его порождает (вычисляет). "Комбинаторные" объекты -- это такие, которые можно пронумеровать, да так, чтобы по номеру сам объект вычислялся. Любые тексты, включая, конечно, стихи, сюда, очевидно, относятся. (Заменим каждую букву "Войны и мира" ее двузначным номером по алфавиту -- получится число, по которому "ВиМ" легко восстановить. Чудовищная огромность этого числа для математика несущественна.) Значит, может быть, стоит к колмогоровской сложности (КС) приглядеться внимательнее.
Идея КС довольно прозрачная: объект "прост", когда его можно коротко описать. Например, фраза из 16 знаков "миллион букв 'А'" порождает текст, который в 62500 раз длиннее ее самой -- этот текст очень прост. Ясно, что текст "Войны и мира" во столько раз не сжать. Однако во сколько раз его можно сжать, совсем не очевидно. WinZip, например, сжимает на 38%. Но ровно настолько же он сжимает текст КСПшных анекдотов из библиотеки Мошкова. Значит ли это, что сложность КСПшных анекдотов такая же, как у "ВиМ"?
Максимально сложный объект -- это такой, который никак короче не описать. Например, случайная последовательность:
0111001100011001110110110101011110110110000111010001111100100001001011Сколько-нибудь заметно сжать случайную последовательность WinZip не сможет, потому что это невозможно вообще. Но значит ли это, что она сложнее "Войны и мира"?
0100001100101110011110010001110010001111110110110100011000011001100111
0111110100111010000011111000010110010101100001101000000010010110000000
1100001110101110000100000001010000001000110110001010000110000010100111
1001110010110100010111001000011001011010000010100000101010100010111100
0100111111110001111010101001001110001010100100001000110101011011110010
1010000110101010000001000101001110111101111000111101111101110010000100
1110010110110111101000110011001110010011000101011011111100110010011101
010101101111001101111000... (и еще 100000 знаков)
Выходит, мы опять столкнулись с той же самой неприятностью, что и
в случае шенноновской информации. КС не измеряет то, что нам
нужно, потому что самым сложным текстом она считает случайную
абракадабру. Да и не удивительно. Удивительно было бы, если бы все
оказалось так просто.
Я, однако, слукавил. Последовательность, которую я выше выдал за случайную (и тем самым, колмогоровски-сложную), на самом деле, порождается очень короткой программой:
nk+1 = ((214013*nk + 2531011) mod 231) ÷ 216
(на каждом шагу печатается 0, если получилось четное число, и 1, если
нечетное).
Вообще-то, конечно, может так оказаться, но нам в нашем поиске термометра это никак не поможет, и вот почему: колмогоровская сложность НЕВЫЧИСЛИМА. WinZip, конечно, несложная программа, но Колмогоров доказал, что и вообще не может существовать такой программы, которая бы вычисляла колмогоровскую сложность любого заданного объекта. Это значит, что можно оставить надежду скормить "ВиМ" компьютеру и узнать, какова длина ее минимальной порождающей программы.
С другой стороны, невычислимость КС означает, что всякое доказательство (не)сложности какого-нибудь конкретного объекта, т.е. отыскание короткого описания (или доказательство того, что короткого описания нет) -- есть принципиально творческий акт. Это очень глубокий и поразительный результат, один из нескольких подобных в математике ХХ века, когда она обратила свои методы на себя самое и доказала, к собственному изумлению, что без интуиции и творчества, одним формализмом, ничего интересного сделать невозможно.
Стихотворема
Повторим, не следует особенно удивляться тому, что колмогоровская сложность не подошла на роль искомого нами измерителя художественности текста. Ведь мы опять предприняли безнадежную попытку измерить содержательность, отвлекаясь от содержания. Текст нужно рассматривать вместе с его смыслом, который можно понимать, например, как фрагмент (объективно-субъективной) реальности, описываемой поэтом, -- или как изменения, производимые стихотворением в сознании читателя. Но если так посмотреть на дело, то в поле идей и образов, связанных с КС, сразу хочется уподобить стихотворение программе, порождающей некоторый объект (смысл, отклик) в вычислительной машине, роль которой играет читатель.И тут КС появляется опять, но не с той стороны, откуда мы ее ждали: оказывается, что стихотворение, как компактное описание (или генератор) большого объекта, есть доказательство колмогоровской НЕсложности этого объекта, своего содержания. Стихотворение -- теорема. Стихотворема.
На первый взгляд это может показаться чепухой: небольшое
стихотворение может сказать нам так много, как целые тома прозы,
какая же тут "несложность"? Во-первых, подчеркнем, что это не
просто "несложность", а "колмогоровская несложность". Это понятие
имеет точный смысл, отношение объема порождающей программы к
объему объекта, и вообще говоря, оно не обязано совпадать с
интуитивным представлением о сложности. И здесь, по-видимому, как раз
и не совпало. Во-вторых, тут очень важна невычислимость КС: бывают
колмогоровски-несложные объекты, для которых компактное описание
найти легко (миллион букв 'А'), но бывают и другие -- вспомним
псевдослучайную последовательность, описываемую простой рекурсивной
формулой. С точки зрения КС, разницы между ними нет, они просты,
однако обнаружить эту простоту в одних случаях легко (в
интуитивном, а не формальном смысле), а в других -- трудно. И не
забудем, что такое доказательство -- всегда творческий акт,
вследствие невычислимости КС. Надо бы различать эти два вида
простоты, обыкновенную (очевидную) и, скажем, неслыханную, ту,
что трудно доказать.
О природе эстетического чувства
Рискуя слишком далеко уйти от основного предмета, хочу все же обсудить вопрос, от которого мы систематически уклонялись: почему, собственно, "информативность" стиха, а вернее трудноуловимое качество, условно обозначаемое здесь этим словом, вызывает эстетическое переживание?
Георгий Кружков в статье "В поисках
Чеширского кота" возводит чувство юмора к древнейшим
человеческим инстинктам.
Информация сама по себе никогда не служит источником этой радости. Научное открытие -- это не накопление информации (фактов), а обнаружение связей и закономерностей, структуры, позволяющей множество фактов описать единообразно и компактно. В некотором смысле, это сокращение количества информации (которую нужно держать в голове), а не ее увеличение. Это обнаружение простоты в том, что казалось сложным. То есть, открытие -- это то же самое, что и стихотворение.
Сходство между поэзией и наукой обнаруживается и на уровне
метода. Поэзия построена на параллелизмах разного рода -- это общее
место. Со(противо)поставление параллельных элементов выделяет
различие в сходном и сходство в различном. Например, в строчках "То
как зверь она завоет, // то заплачет, как дитя" "дитя"
сопоставляется со "зверем"; гласные переднего ряда "е", "о" -- с
гласнoй заднего ряда "а"; положение обстоятельства перед
сказуемым с его положением после сказуемого.
Понятно, что способность к обнаружению связей и закономерностей
-- это фундаментальная функция мозга, и не только человеческого,
но только у человека она возвысилась до роли главного эволюционного
приспособительного механизма биологического вида. Неудивительно
поэтому, что упражнение этой способности должно доставлять
человеку такое же удовольствие, как, допустим, зайцам -- прыжки по
лужайке.
Назад, к эмпирике
Но нас занесло далековато в эмпиреи, между тем, как мы хотели отыскать что-нибудь измеримое ("ибо всякая наука лишь тогда..."). Подведем промежуточный итог наших разысканий. Похоже, что все до сих пор так или иначе вращалось вокруг двух основных идей, связанных с понятием структурного богатства текста или, шире, произведения:
1. Структурное богатство служит источником эстетического
переживания, если оно доступно интуитивному восприятию.
2. Структурное богатство произведения позволяет ему быть содержательно емким (мы старательно избегаем слов "сложность" и "информация") -- в том ли смысле, что оно описывает большой фрагмент реальности, или в том, что оно вызывает нетривиальный отклик у читателя/зрителя.
На первую идею вряд ли возможно навести сколько-нибудь количественную теорию, потому что для этого нужно было бы построить научную модель эстетически воспринимающего субъекта. Вторая идея, кажется, содежит в себе потенциал для математической формулировки и, может быть, даже доказательства. Наверное, можно было бы попробовать построить модель некоторого языка и описываемой им реальности (хотя бы это был язык программирования и объекты, порождаемые программами на нем) и показать, что компактности программ-описаний можно добиться только усложняя (в каком-нибудь смысле) язык.
Но мы хотим работать с реальными текстами. Очевидно, экспериментальная проверка обеих идей требует прежде всего научиться измерять это самое "структурное богатство". Как?
Представляя себе несколько наивно структуру как множество элементов
и связей между ними, можно было бы определить богатство как,
например среднее количество связей, приходящихся на один
элемент. Следуя по этому пути, мы должны были бы определить, что
считать элементами, завести номенклатуру возможных связей и
пуститься в анализ текстов с подсчетами. Наверное, это можно
делать, хотя пришлось бы преодолевать множество трудностей и
допускать сильные упрощения. Элементами структуры пришлось бы
считать отдельно слова, отдельно звуки, из которых они состоят,
отдельно грамматические категории и т.д. и т.п. Еще труднее
пришлось бы со связями: как учесть, например, обсуждаемое Р. Якобсоном
преобладание множественного числа в нечетных строфах стихотворения
Блока "Девушка пела в церковном хоре", а единственного -- в четных?
("И вообще, резкая морфологическая и синтаксическая
противоположность между нечетными и четными строфами".)
Сколько это связей на сколько элементов? Наконец, труднее всего было
бы обосновать реальность учитываемых связей, т.е. то, что они
действительно воспринимаются читателем, а не являются
артефактами анализа (в чем многократно упрекали Якобсона). Вдобавок,
связи, очевидно, бывают разной силы, скажем, ассонанс слабее
рифмы. Но как оценить силу связи числом?
Но плодотворнее другой путь. Прежде всего надо заменить метафору
связи как некой веревочки, связывающей два элемента, на
метафору пут, ограничивающих свободу выбора. Например, слово в
строке пятистопного ямба не столько "связано с" остальными словами,
с каждым по отдельности, сколько "связано" ритмическим полем,
задаваемым ими всеми вместе. Это поле ограничивает свободу выбора
этого слова. Конечное слово строки рифмованного стиха связано
сильнее: оно должно рифмоваться. Каждое слово в стихе связано и
обыкновенным синтаксисом и семантикой, и много еще чем.
В пределе слово может оказаться так сильно связанным, что никакого другого на его место подставить будет нельзя без ослабления структуры. Но не получится ли в таком предельном случае стопроцентно предсказуемый и потому неинтересный текст? Совсем не обязательно -- представьте себе трудный кроссворд. Каждое слово в нем однозначно задано пересечением с другими и вдобавок определением, и тем не менее найти его может быть совсем непросто.
Это очень важное обстоятельство, на котором стоит остановиться,
потому что оно разрешает парадокс, на который мы дважды натыкались
выше: случайная абракадабра "сложнее" и "информативнее" любого
осмысленного текста. Каждое слово в художественном тексте
должно быть одновременно непредсказуемым и единственно
возможным.
Кажется, мы кое-что нащупали; повторим, приглядимся, попробуем
на зуб. Было у нас две крайности: текст, абсолютно предсказуемый, где
каждое слово определяется однозначно предыдущими, -- и текст
абсолютно непредсказуемый, где на следующем месте может стоять
любое слово вообще. Первый неинтересен, второй бессмыслен (и тоже
неинтересен), а все остальное лежит на прямой между этими
крайностями. Разорвав пропроциональность между предсказуемостью и
связанностью (обратное количество возможных вариантов), мы
вырвались с прямой, ведущей от банальности к абракадабре, на
плоскость двух независимых координат.
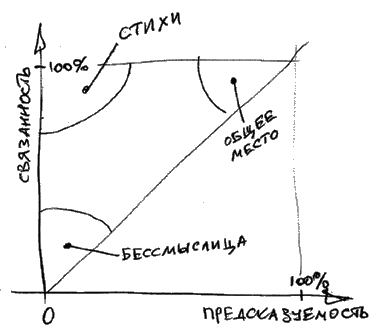
Механизм низкой предсказуемости при высокой связанности можно
схематически представлять так: слово (или другой элемент текста)
связано одновременно несколькими силовыми полями разной природы:
ритмическим, синтаксическим, семантическим, фонетическим и
т.д. Предположим, что стопроцентно удовлетворительного решения
получающийся кроссворд не имеет. Тогда приблизительные решения
могут подчиняться общеязыковым связам (синтаксис, буквальная
семантика) игнорируя специфические художественно-языковые
(фонетика, ритмика, метафорическая семантика), -- либо наоборот,
подчиняться вторым за счет вольного обращения с первыми. Оба
варианта могут иметь примерно одинаковую степень связанности, но
второй значительно неожиданнее в силу мощной общеязыковой
инерции читателя.
(Ср. сказанное 4-мя абзацами выше об уравнивании общеязыковых и
чисто-стиховых организующих факторов.) Тут, конечно, следует
множество оговорок, поскольку "неожиданность" -- характеристика
существенно субъективная, и для читателя, натренированного на
определенный, допустим, метафорический, стиль, именно пренебрежение
метафорой там, где он ее ожидает, в пользу общеязыковой семантики
может произвести художественный эффект.
Дело техники
Дальше, в общем-то, уже понятно. Характеристикой текста будут служить два числа, а не одно: степень связанности слов в нем и степень их предсказуемости.С точки зрения интуитивного, синтетического восприятия, связанность -- это то качество текста, которое создает ощущение, что все слова стоят на своих местах. Проверить его можно (по крайней мере, мы на это надеемся), если заменить правильное слово неправильным, такая замена должна непосредственно ощущаться. Конечно, понятие "неправильного" слова расплывчато. Что можно подставить вместо последнего слова в строчке "Вихри снежные крутя"? Неправильной по всем параметрам будет замена вроде "Вихри снежные помидор" (впрочем, Введенского напоминает; но для Пушкина, конечно, немыслимо). "Вихри снежные вращая" не подходит по размеру и рифме, "платя" -- по смыслу, "Вихри снежные -- оттяг" невозможно по стилистике. А как насчет "Вихри снежные вертя"? А "Вихри снежные чертя"?
Представим себе, что мы умеем определять, насколько хорошо подходит любое данное слово на данное место в тексте. Эта оценка, конечно, не может быть вполне объективной, но нас интересует статистическое среднее по гипотетической большой и однородной группе квалифицированных читателей. Тогда одно или несколько слов подходят наилучшим образом, сколько-то подходят, но слабее, сколько-то еще слабее и так далее. Предложим читателю сравнить два слова на подходящесть: авторское (предполагая его наилучшим) и одно из приблизительных. Чем выше связанность текста в этом месте, тем больше будет разница между "тем самым" словом и приблизительным, тем легче будет читателю ее уловить и угадать, которое из слов -- авторское. Это дает нам методику измерения связанности. Другой вариант -- предъявить одно слово и предложить угадать, авторское оно или замена. Неясно априори, какой метод лучше, стоит испытать оба.
Подытожим. Мы будем измерять предсказуемость вероятностью
правильно угадать пропущенное слово. Точнее, мы будем измерять
непредсказуемость отрицательным двоичным логарифмом этой
вероятности.
Связанность мы будем измерять двумя способами, с предъявлением
одного или двух слов (из которых одно авторское), назовем их
связанностью А и связанностью B. И ту, и другую определим
формулой
Каких следует ожидать результатов? Как минимум, статистически
значимых различий между различными категориями
текстов. "Категорию" могут составлять, например, "сонеты Шекспира в
переводе Маршака", "стихи Хармса" или "передовицы газеты
Правда". Если различий не обнаружится, то либо неверна гипотеза о
значимости структурного богатства текста для его эстетического
восприятия, либо неудачен метод измерения (либо и то, и
другое). Если различия обнаружатся, то мы ожидаем, что
заведомо высокохудожественные тексты будут иметь повышенные
значения как непредсказуемости, так и связанности по сравнению с
малохудожественными и нехудожественными.
Надо ясно понимать, что мы измеряем не столько объективные
параметры текста, сколько объективные характеристики субъективного
восприятия этого текста конкретными читателями.
На этом, пожалуй, стоит поставить точку и подождать результатов
эксперимента.
Я чрезвычайно признателен Ю. Манину, М. Вербицкому, Ю. Фридман, Р. Лейбову, Г. Минцу и многим другим за многочисленные поучительные и занимательные обсуждения затронутых здесь тем.
Литература по теме -- аннотированный рабочий список
Публикации
- D.Yu. Manin. The Right Word in the Left Place: An experimental study of lexical foregrounding. Scientific Study of Literature, 2012. Рукопись см. на academia.edu
- Д.Ю. Манин. Освобожденный стих или нарубленная проза? Экспериментальное исследование русского верлибра, доклад на конференции по количественными методам в искусствознании, Екатеринбург, ЕМИИ, 2012. Тж. в сборнике материалов конференции: "Количественные методы в естествознании", Артефакт, Екатеринбург, 2012.
- D.Yu. Manin. Chopped-up Prose or Liberated Verse? An experimental study of Russian vers libre. Modern Philology, 108(4), pp. 580-596.
- Д.Ю. Манин, Из песни ... не выкинешь. Опыт экспериментальной поэтики. Препринт "Рутении", октябрь 2009.
- D.Yu. Manin. Experiments on predictability of word in context and information rate in natural language. J. Information Processes (electronic publication, http://www.jip.ru), 2006, Vol. 6, No. 3, pp. 229--236. См. тж. дополненный русский текст.