| Комментарий 80 к комментируемому месту / к оглавлению: диалогическому, хронологическому, монологическому | |
| Автор: | M, manin@pobox.com |
| Дата: | 05/07/2004 10:30 |
| Резюме: | Предварительная сводка экспериментальных данных |
Предварительная сводка экспериментальных данных
Я начинаю публиковать здесь разнообразную экспериментальную статистику. Поначалу практически без комментариев. Данных много, и на их осмысление уйдет много времени. Комментарии к этому тексту разрешены, но поскольку текст может меняться, они могут устаревать. Все графики показываются в увеличенном виде в новом окне по щелчку мышью.
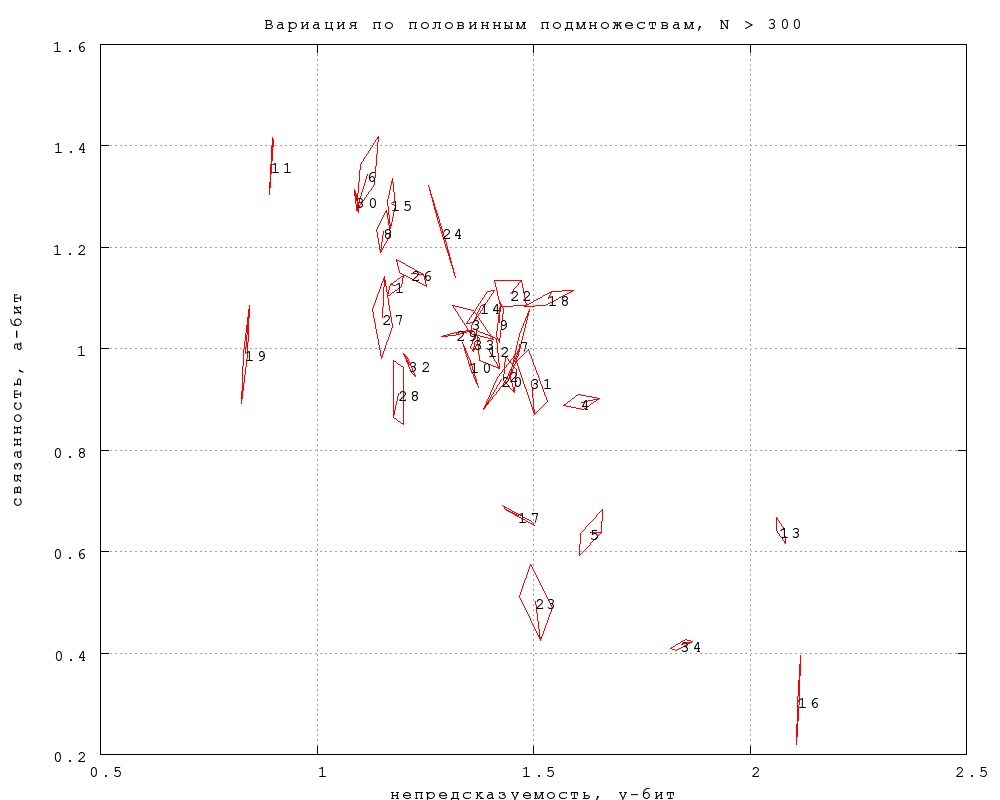
1. Статистическая изменчивость
Для оценки статистической погрешности измерения ниже сравниваются
результаты (непредсказуемость и связанность B), вычисленные по всем
попыткам, с результатми, вычисленными только по половине попыток -- по
четным, по нечетным, по попыткам, номер которых < 2 mod 4
или > 1 mod 4. В результате каждая категория текстов представлена
на графике центральной точкой и описанным вокруг нее
четырехугольником, вершины которого соответствуют результатам по
четырем половинным подмножествам. Размер четырехугольника
ориентировочно соответствует погрешности измерения центральной точки
(а вернее, приблизительно в полтора раза превышает ее). Черные числа
-- номера категорий. Категории 5, 17 и 23 -- прозаические, 13, 16 и 34
-- Введенский, Хлебников и Хармс (не обязательно в этом порядке), 19
-- тосты и поздравления, 11 -- Доризо, 6 -- Шекспир/Маршак, 18 --
стихи Пастернака.
Фиг. 1
То же, но с учетом только попыток игроков, сделавших более 300 попыток
каждый (в дальнейшем будем называть их "опытными-300"; это примерно
каждый 15-й, и на их долю приходится около 2/3 всех попыток) и, среди
заданий типов 2 и 3, только с заменами от опытных-300
игроков. Разброс выше, чем на предыдущем графике, потому что часть
попыток отфильтрована, данных меньше, выше статистическая
погрешность.
Фиг. 2
Красные хвосты показывают, что более опытные игроки лучше угадывают и
лучше определяют замены, практически независимо от категории
текстов. Зеленые хвосты проходят ниже красных, поскольку у опытных
игроков и замены более правдоподобные, т.е. их труднее отличить от
авторских слов, и связанность, рассчитанная по ним, оказывается
несколько ниже. Для некоторых категорий этот эффект оказывается
незначительным (зеленый и красный хвосты почти совпадают), для других
он преобладает (зеленый хвост идет не вверх, а вниз), но неясно,
насколько этот результат статистически значим.
Существенно, что взаимное расположение точек принципиально не меняется
при отбрасывании менее опытных игроков, возможно, за отдельными
исключениями, которые мы рассмотрим ниже.
Фиг. 3
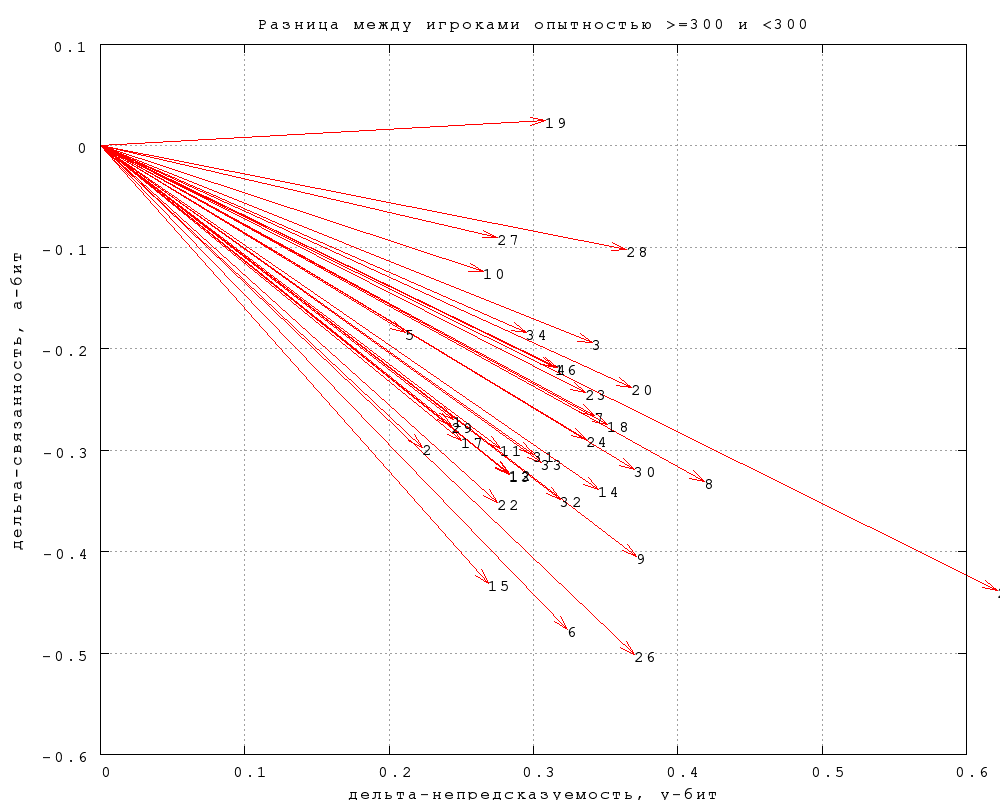
На фиг. 4 показана разница между данными по игрокам с опытностью
меньше и больше 300. Стрелки указывают, как меняются непредсказуемость
и связанность при переходе от первых ко вторым.
Фиг. 5
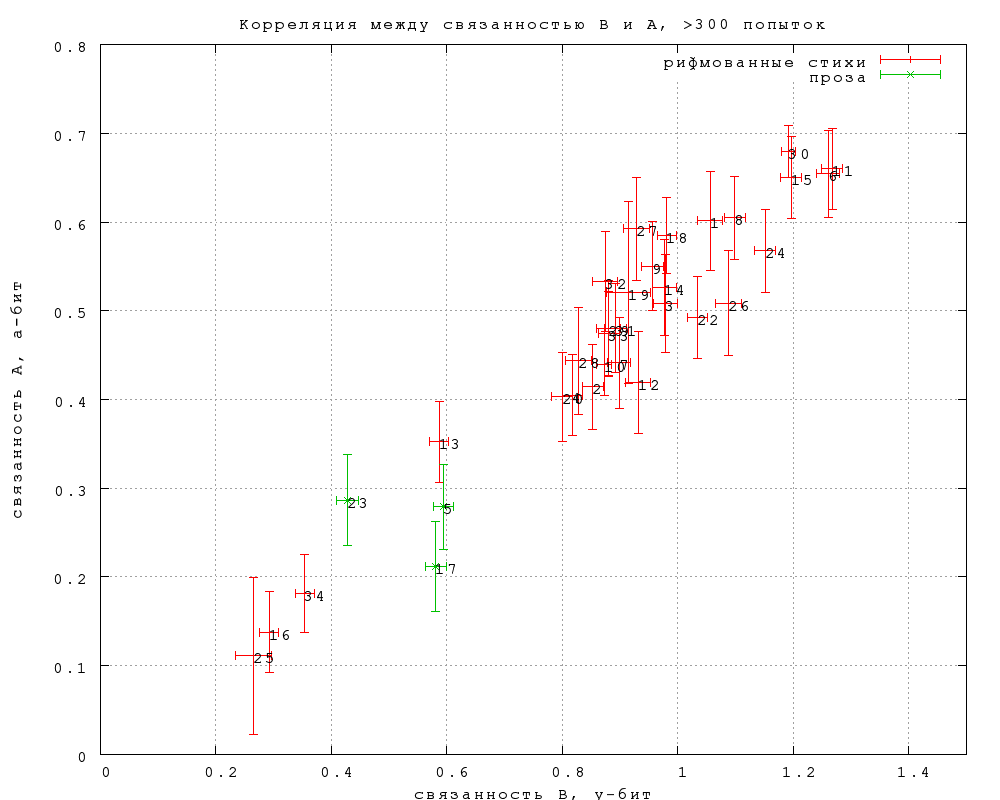
Связанность C, которая отличается тем, что в ее определении
минимизировано влияние качества замен, неожиданно оказалась в
среднем равна связанности B. Однако разброс превышает статистическую погрешность, и
отклонения от равенства (не все, но многие) могут быть статистически
значимы. В первом приближении можно считать, что связанность C
значимо ниже связанности B (значимо выше она не бывает) у тех
текстов, в которых в среднем труднее придумать убедительную замену.
Фиг. 6
Связанность A оказывается в
пределах статистической погрешности ровно половиной связанности B
(обратите внимание на разный масштаб по осям на фиг. 6). Это
довольно неожиданный результат, поскольку связанность -- величина
логарифмическая от вероятности, и если бы вероятности находились в
пропорциональной зависимости, их логарифмы отличались бы на
константу. Объяснение находится, если рассмотреть еще одну
разновидность связанности (D), определив ее так же, как C, но по
попыткам с предъявлением замен, а не авторских слов -- см. фиг. 7 ниже.
Фиг. 7
Связанность D оказывается некоррелированной с остальными
разновидностями. Поскольку связанность A есть, грубо говоря, среднее между C и
D, а C приблизительно равна B, это объясняет, почему A вдвое меньше
B. Сама по себе некоррелированность связанности D любопытна -- это
указывает на то, что мы имеем дело с двумя разными явлениями, когда
рассматриваем опознание авторского слова и замены. Очевидно, во втором
случае существенную роль играет то, насколько трудно придумать
убедительную замену.
Фиг. 9
Фиг. 10
Фиг. 11
Различия существуют, но находятся на грани статистической значимости,
особенно по связанности. Тот факт, что непредсказуемость слегка выше,
по слепым попыткам, неудивителен, замечательно скорее, что эффект
очень невелик. Влияние на предсказуемость еще слабее и противоречиво,
что может объясняться чисто случайными причинами. По крайней мере, данных пока
недостаточно, чтобы утверждать, что замены, сделанные вслепую,
получаются убедительнее сделанных в открытую.
Главное, что следует заключить из этого и предыдущего разделов, --
различия между категориями не объясняются такими факторами, как
общее знакомство испытуемых с текстами и неравномерностью средней
длины фрагмента, а свидетельствуют о значимой разнице во внутреннем
устройстве самих текстов.
Фиг. 12
Фиг. 13
Фиг. 14
Фиг. 15
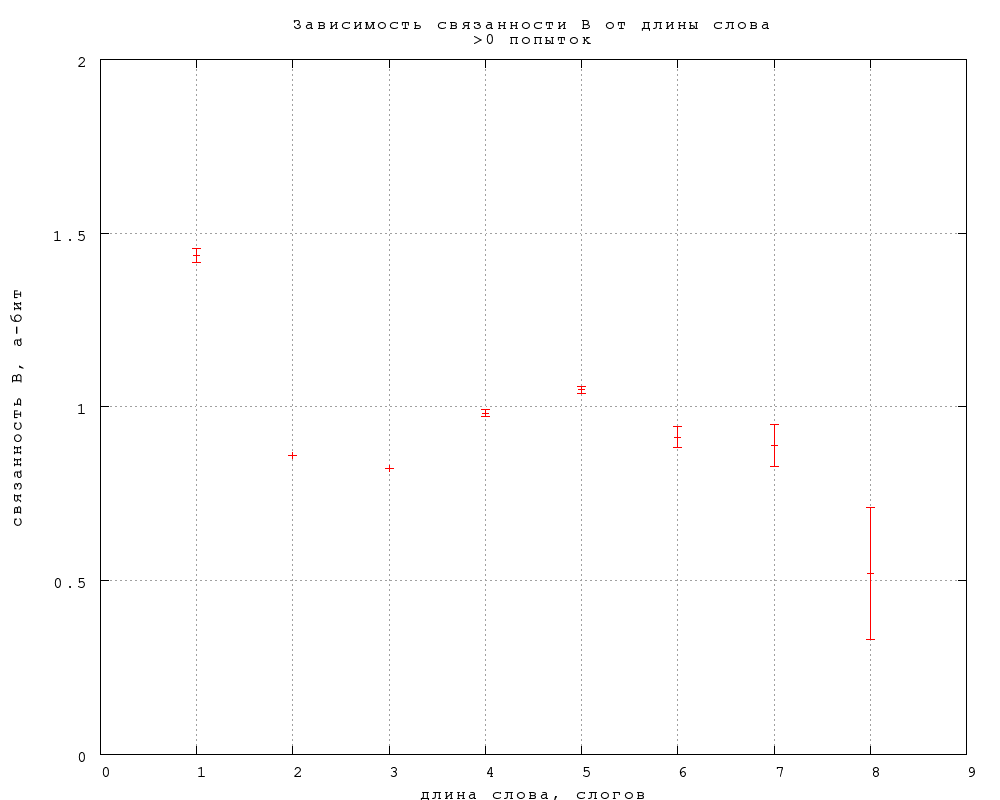
Связанность же оказывается в первом приближении не зависящей от длины
слова, если не считать небольшого понижения на словах средней длины, 6-7
букв или 2-3 слога. Такая принципиальная разница между связанностью и
предсказуемостью требует объяснения. Возможно, она связана
просто с тем, что в заданиях 2-го и 3-го типа мы выбираем из двух
вариантов ответа, независимо от длины слова, но могут быть и более
содержательные объяснения.
Фиг. 16
Фиг. 17
Фиг. 18
Фиг. 19
Фиг. 20
Фиг. 21
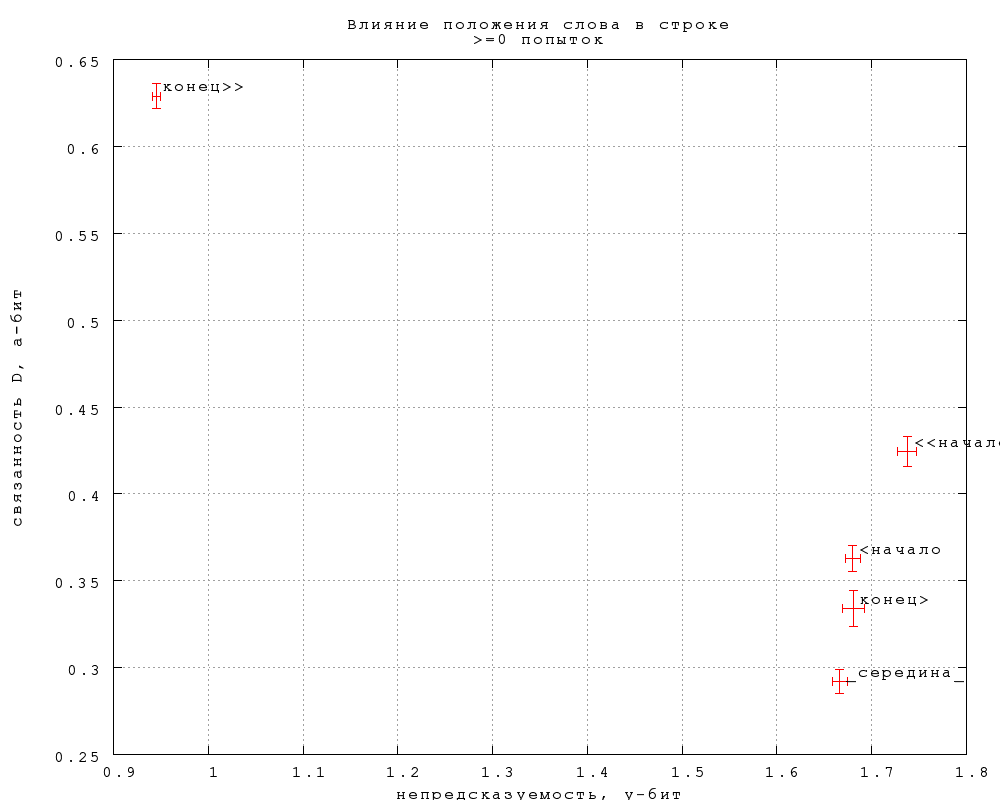
На фиг. 22-24 мы различаем 5 различных позиций: строгое начало, когда
слову ничего не предшествует в строке, кроме знаков препинания;
нестрогое начало, когда ему предшествуют слова короче 5 букв;
аналогично строгий и нестрогий конец строки; все прочее считается
серединой. Если слово длиннее 5 букв в строке одно, то оно считается
концевым.
Видно, что строгие концы разительно отличаются от всех остальных
позиций, как и следовало ожидать (в меньшей степени по связанности
D). Из остальных позиций строгие начала несильно, но значимо
непредсказуемее. Три серединные позиции практически не отличаются по
предсказуемости, а отличия по связанности если и есть, то недостаточно
выражены, чтобы приобрести статистическую значимость при нынешнем
числе попыток (полмиллиона).
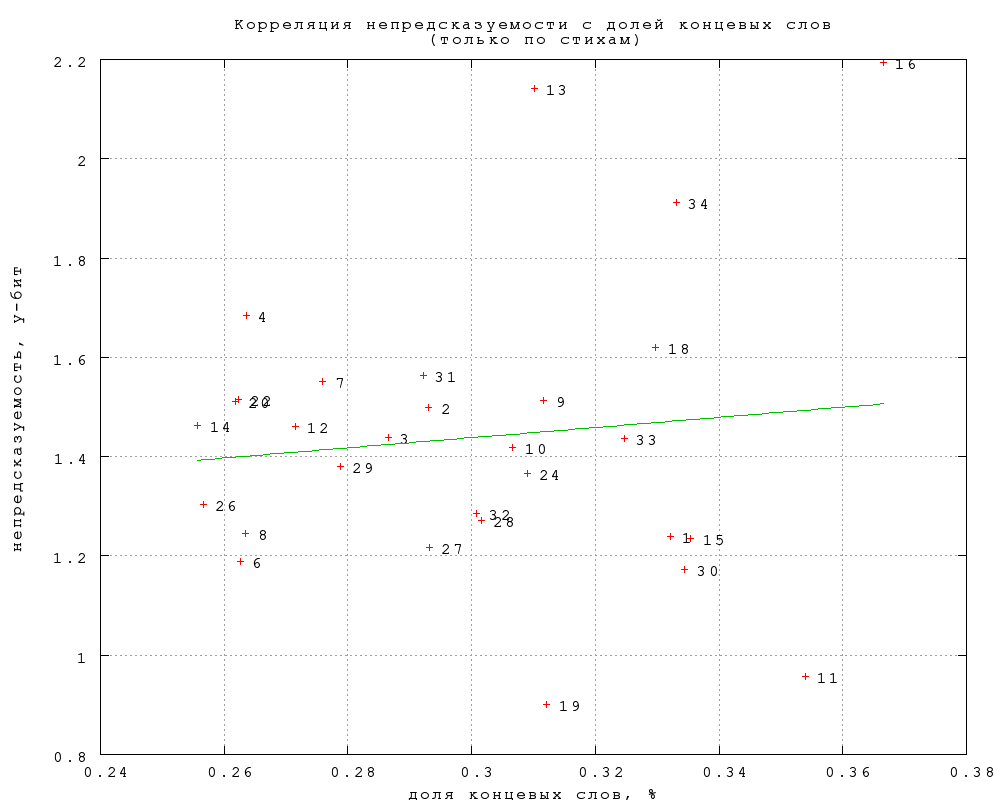
Учитывая, что между категориями имеются систематические различия в
длине строк, а следовательно, и в доле слов в концевой позиции,
следует проверить, не объясняются ли, хотя бы частично, различия между
категориями этим фактором. Фиг. 25 показывает, что корреляция между
долей концевых слов и непредсказуемостью в категории
отсутствует. Показательно, что среди категорий с особенно короткими
строками есть как самые предсказуемые, так и самые
непредсказуемые. Этот вывод не меняется от того, учитывать ли только
строго концевые позиции, или вместе с нестрогими. Таким образом, мы
снова убеждаемся, что различия между категориями не объясняются
"внешними" факторами.
Фиг. 22
Фиг. 23
Фиг. 24
Фиг. 25
Прежде всего прочего этот график показывае, что статистика еще далеко
не достаточная для выводов по отдельным текстам (не говоря уже об
отдельных фрагментах). Тем не менее, можно уже, по-видимому, говорить
о том, что разброс точек значимо меньше у однородных
категорий. Интересно, что в обоих случаях облако точек имеет отчетливо
вытянутую форму, но от интерпретаций тут пока следует воздержаться.
Фиг. 26
Фиг. 27
Для характеристики метрического аспекта угадываемости мы используем
величины, построенные аналогично непредсказуемости и
связанности. Метрической непредсказуемостью назовем отрицательный
двоичный логарифм вероятности правильно угадать слоговую длину
пропущенного слова (в том числе если слово угадано
неправильно). Определение метрической связанности сложнее. Если
(полная) связанность измеряет, насколько авторское слово хорошо
отличимо от замен, то метрическая связанность измеряет, какая доля
этой отличимости возникает за счет несовпадения слоговой длины
слова. Мы определяем ее как отр. дв. логарифм отношения двух
вероятностей -- правильного ответа в задании типа 3, если замена имеет
правильную или неправильную длину.
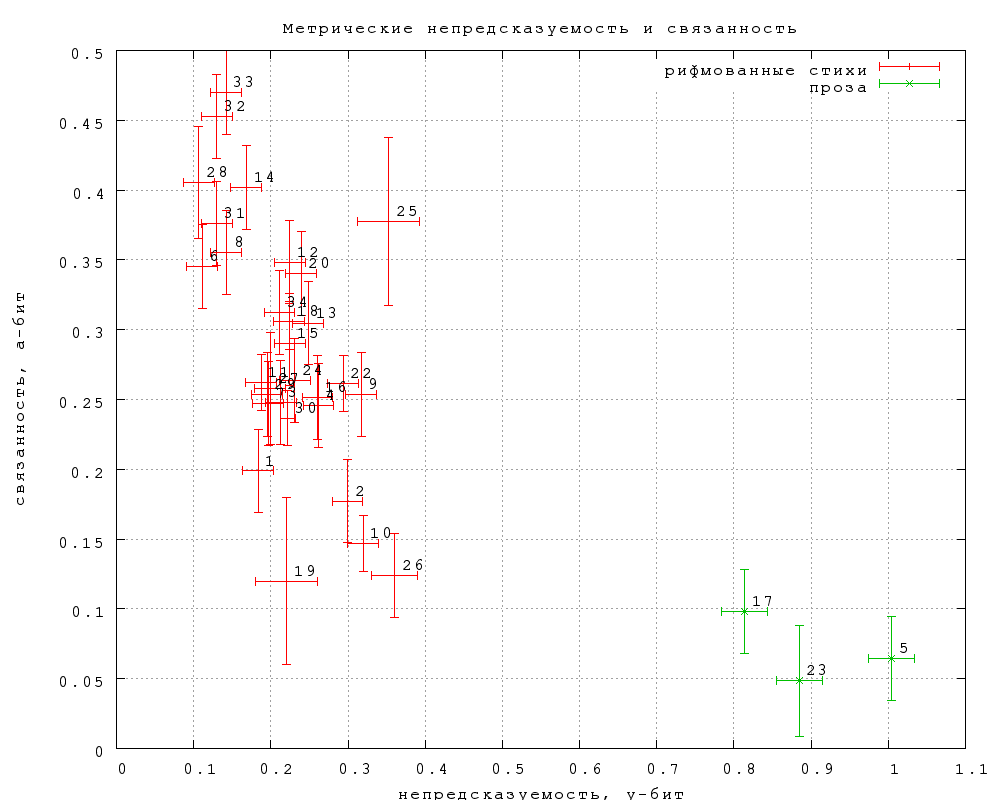
Фиг. 28 показывает распределение этих двух величин для первого
этапа. Для прозы метрическая непредсказуемость значительно выше, чем
для стихов, преимущественно силлаботонических рифмованных в этом
этапе. Метрическая связанность прозы близка к нулю, но значимо выше у
стихов. Эта картина вполне согласуется с интуицией. Самая высокая
метрическая связанность у поэзии XVIII века и переводов Шекспира (а
также почему-то у Ахмадулиной). Самая низкая -- у любительских стихов
("тосты и поздравления", стихи.ру, "Самиздат"), а также
у текстов песен Щербакова, которые часто полиметричны. Отдельно
стоящая точка 25 -- это "Шитверочестия" С.Шпикуна.
Среди более тонких эффектов отметим, что метрическая связанность
прозы, по-видимому, значимо отлична от нуля, хотя и очень невелика, и
что в этой системе координат проза Пастернака сдвинута от прозы
Л.Толстого в сторону поэзии.
Фиг. 28
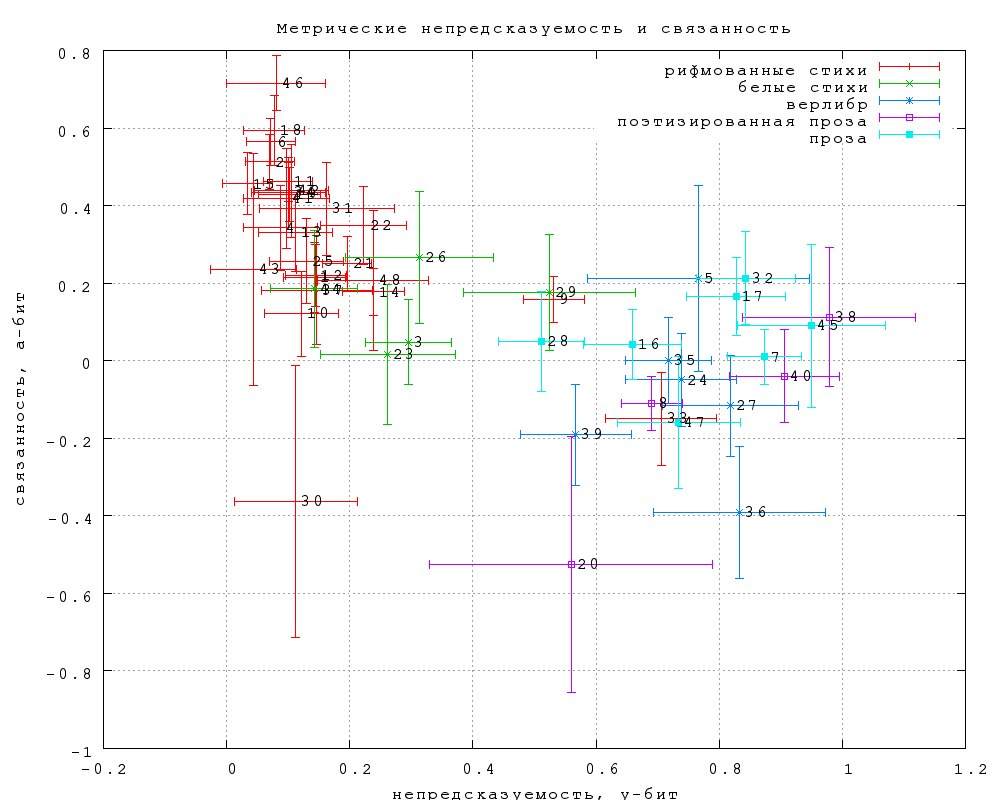
Исследованию отличий между прозой поэзией и промежуточными формами
посвящен, в частности, второй этап. Несмотря на крайне ограниченный
пока экспериментальный материал, приведем здесь соответствующий
график с оговоркой, что результаты пока не могут считаться надежными
-- см. фиг. 29. Здесь следует прежде всего обратить внимание на
взаимное расположение прозы и рифмованных стихов, повторяющее
результаты первого этапа. (Отдельные выпадающие точки сейчас
обсуждать преждевременно.) Это позволяет надеяться на надежность данных
и для других классов текстов. Замечательно обнаруживающееся здесь
противопоставление прозы и белых стихов с одной стороны -- верлибру и
"поэтизированной прозе" с другой по знаку метрической связанности:
верлибр демонстрирует тенденцию к отрицательным значениям. Это значит,
что в заданиях типа 3 (на выбор) с верлибром правильно ответить
труднее, когда предлагаемые слова разной длины, а не легче, как в
случае силлаботонических стихов. Возможно, причина этого в том, что
когда надо выбирать из слов разной длины в верлибре, слоговую длину слова
приходится учитывать как выразительное средство (а не формальное ограничение), в результате чего
повышается размерность пространства критериев, и выбор становится труднее. Если этот результат подтвердится в
дальнейшем, он может пролить новый свет на роль метрической
организации в верлибре и смежных формах.
Фиг. 29
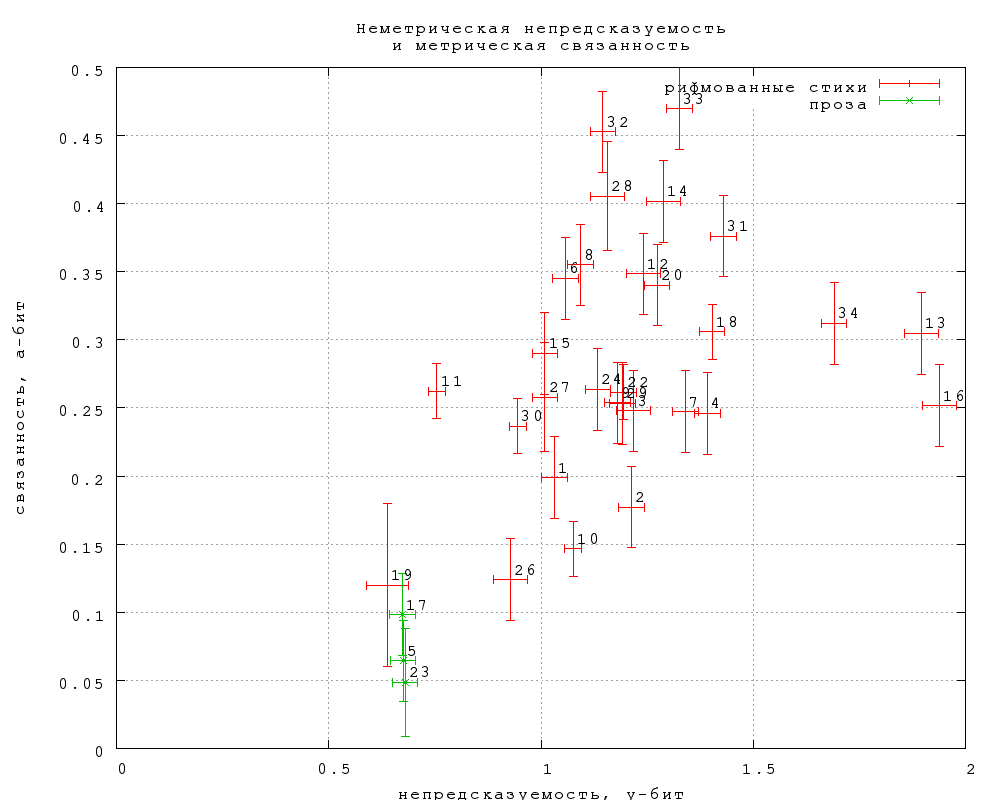
Представляет интерес еще одна величина, которую мы обозначим как
"неметрическую непредсказуемость" за отсутствием менее уродливого
термина. Это просто разность между полной и метрической
непредсказуемостью. Она характеризует вероятность угадать слово при
условии, что его слоговая длина известна (уже угадана). Она, таким
образов как бы снимает преимущество в непредсказуемости, которое имеет
проза по сравнению со стихом за счет метра. Результаты представлены на
фиг. 30. Оказывается, что с метрической подсказкой непредсказуемость
прозы становится меньше, чем у любых стихов (и на уровне "тостов и
поздравлений").
Фиг. 30
Продолжение следует

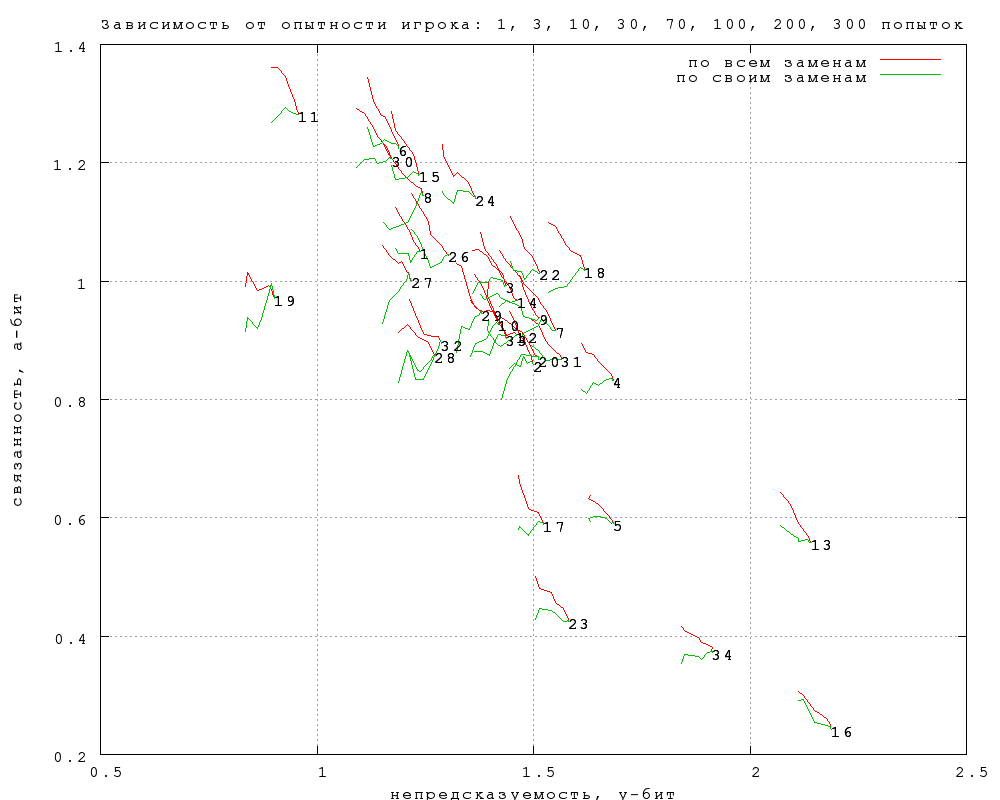
2. Влияние опытности игроков
Таблица результативности игроков показывает, что опыт в игре
систематически влияет на результативность. Вероятно, сказывается и то,
что игра интереснее тем, кто лучше чувствует тексты, и то, что
накапливается опыт в отгадывании именно тех текстов и авторов, которые
включены в игру. Соответственно, результаты зависят от того, брать ли
все попытки или только принадлежащие более опытным игрокам. Следующий
график изображает эту зависимость. Цифры отмечают точки, рассчитанные
по всем попыткам. Красные и зеленые хвосты проведены от них через
точки, рассчитанные по подмножеству попыток, принадлежащих игрокам,
сделавшим более N попыток, при изменении N от 1 до 300 (т.е. все более
опытным). Отличаются они тем, что красные рассчитаны по всем попыткам,
сделанным этими игроками, а при рассчете зеленых дополнительно
отброшены попытки, в которых игрокам с опытностью >N предъявлялись
замены, сделанные менее опытными игроками.
3. Корреляция между разновидностями связанности
На фиг. 5 и 6 показано, как соотносятся между собой значения
связанности, измеренные тремя различными способами: связанность B
(основная) -- по заданиям типа 3 (выбор из двух вариантов),
связанность A -- по заданиям типа 2 (опознание выделенного слова) и
связанность C -- тоже по заданиям типа 2, но только по тем попыткам, в
которых предъявлялось авторское слово.


4. Зависимость от длины фрагмента
Угадываемость слова, вообще говоря, может зависеть от длины
фрагмента -- например, потому что в более длинном фрагменте больше
перекрестных отношений между словами, связей, подсказок. Поэтому
разница между категориями может, по крайней мере отчасти, проистекать
от того, что в некоторых категориях фрагменты в среднем длиннее, чем в
других. Фиг. 8-12 показывают, что этот эффект пренебрежимо мал. На них
изображены зависимости предсказуемости и связанности B от длины
фрагмента в словах. Чтобы выделить зависимость от длины фрагмента в
чистом виде, данные обрабатывались следующим образом:
Зеленые прямые -- наилучшее линейное приближение. Во всех случаях их
наклон оказывается пренебрежимо мал и статистически незначим. Таким
образом, разницу в средней длине фрагмента можно не учитывать при
обработке результатов.
Фиг. 8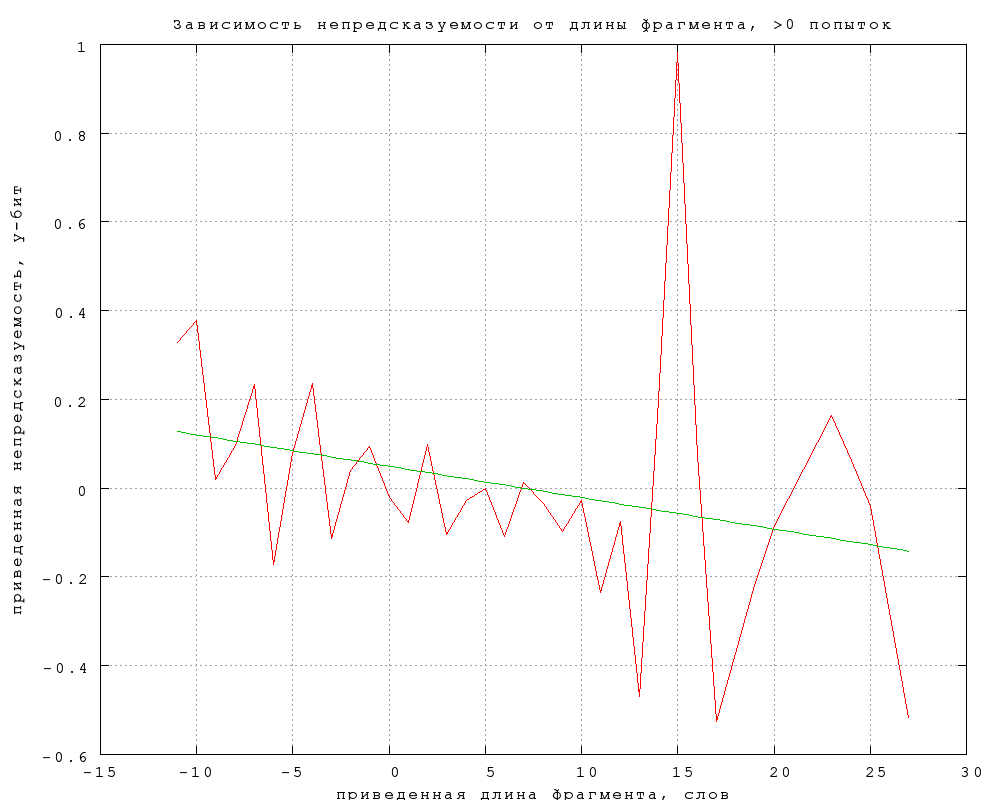



5. Влияние открытости автора и названия
На фиг. 12-15 показано, как влияет на результаты предъявление игроку
автора и названия фрагмента. На каждом графике нанесены 4 точки, в
соответствии с тем, видел ли автора и название угадывавший игрок и
игрок, предложивший замену (если в попытке участвовала замена). Так,
пометка "вслепую/в открытую" означает, что угадывавшему не
показывалось, а автору замены показывалось. Приведены данные по всем
игрокам и по игрокам с опытностью 300, по связанности B и связанности
D.

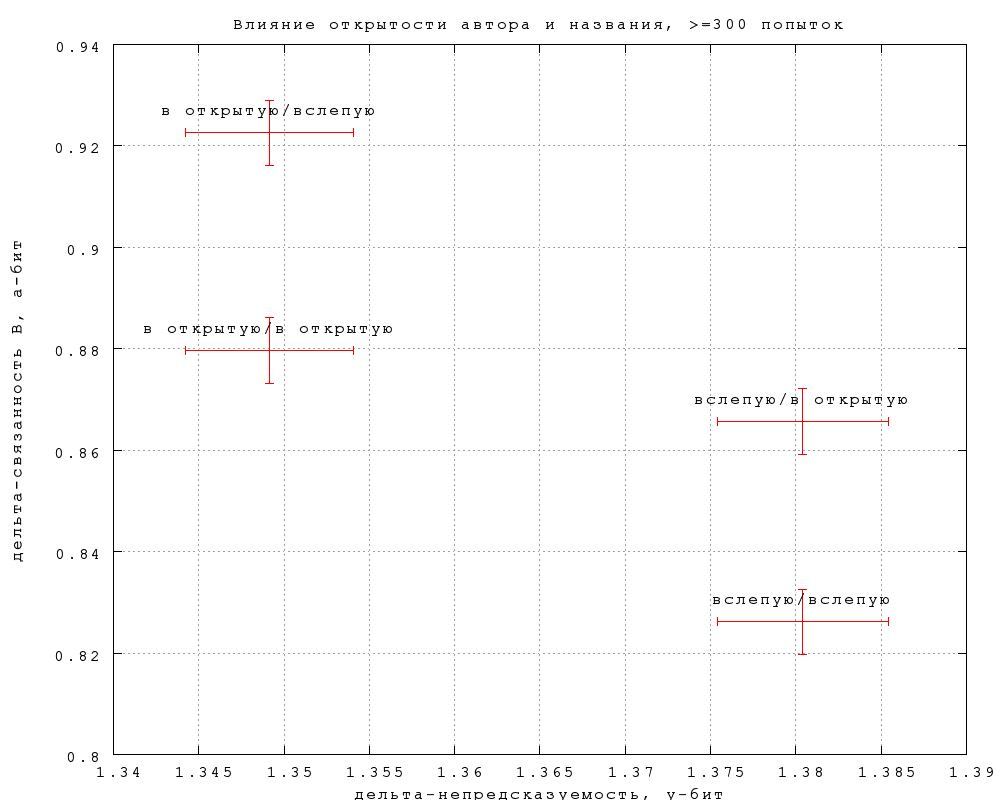


6. Зависимость от длины слова
Зависимость непредсказуемости и связанности B и C от длины слова,
выраженной в буквах и слогах, приведена на фиг. 16-21. Примечателен
линейный рост непредсказуемости, в полном согласии со
стандартной теорией информации, в предположении о статистической
независимости букв в слове. Буквально оно не справедливо, конечно, но
этот линейный рост показывает, что количество (равноправных)
вариантов, которое мы рассматриваем, угадывая слово, растет
экспоненциально с увеличением длины слова. 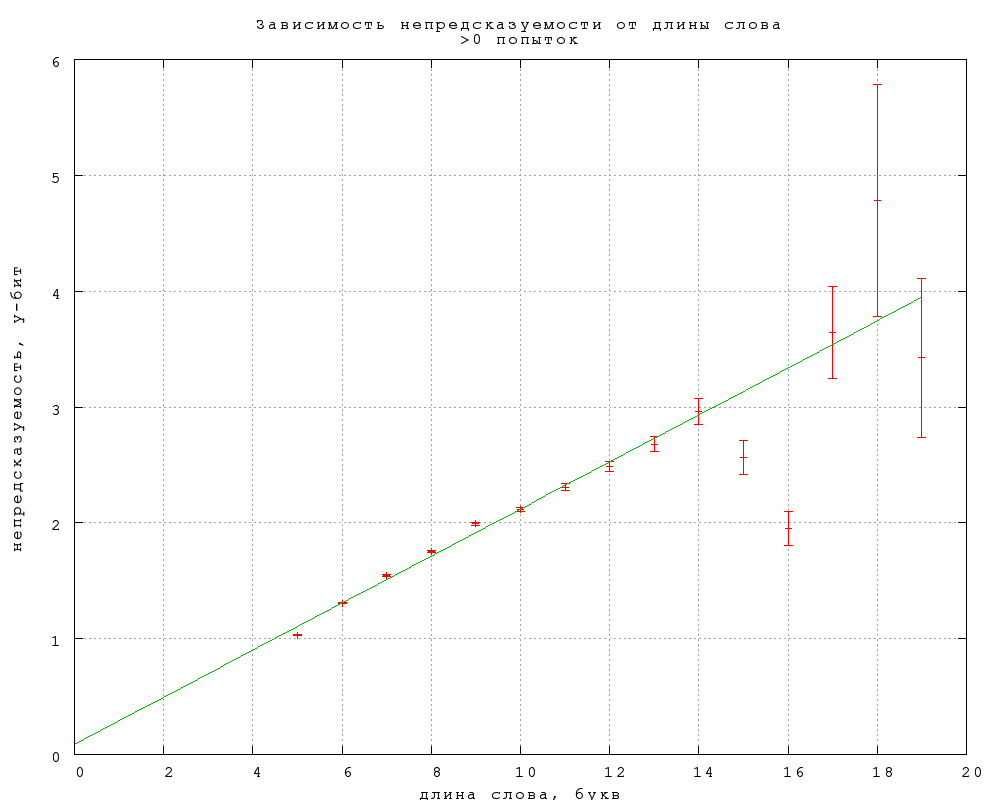

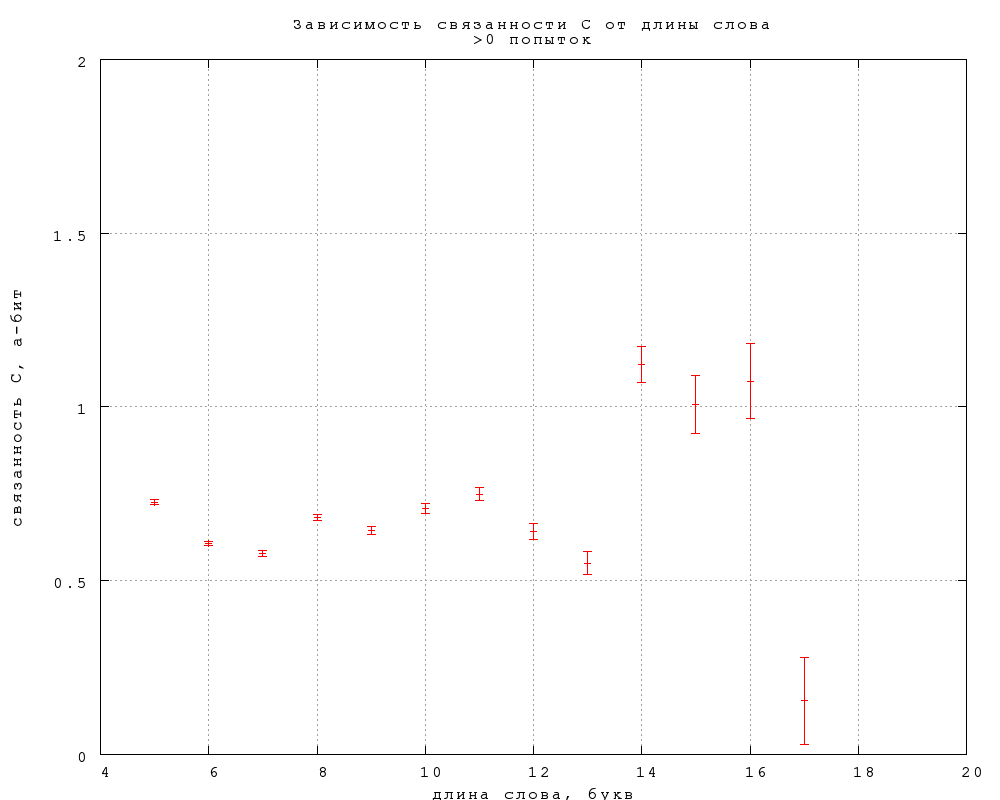


7. Влияние положения слова в строке
Очевидно, непредсказуемость слова сильно понижается, если это слово
участвует в рифме. Менее очевидно, но опытному игроку известно, что
слово, стоящее в начале строки, угадать труднее. (Позиции в начале,
середине и конце строки, согласно М.Л. Гаспарову, различаются даже
семантически: в поэме "Соловьиный сад" Блока начала строк содержат
больше слов, относящихся к герою и его действиям, середины -- к
героине, а концы -- к фону действия.)


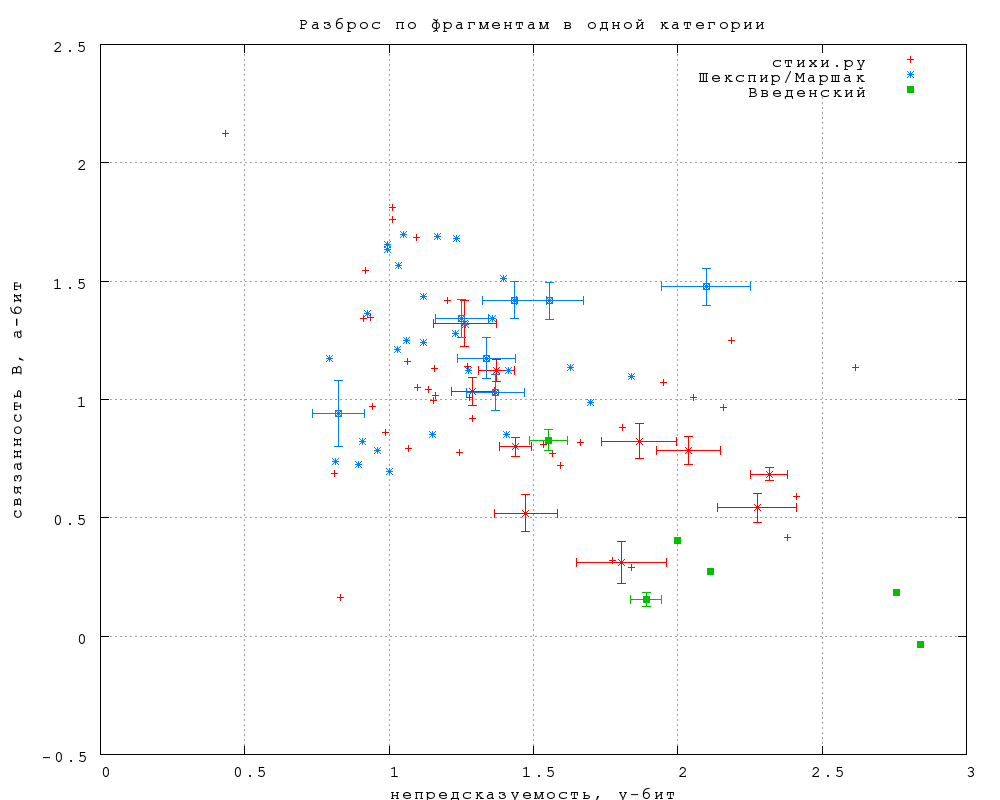
8. Разброс внутри категории
Насколько оправданно объединение текстов в категории? На фиг. 26
показаны данные по отдельным текстам в трех категориях -- самой
однородной (Шекспир/Маршак), самой неоднородной (стихи.ру) и
промежуточной (Введенский). Теоретическая оценка статистической
погрешности показана только для некоторых точек, чтобы не загромождать
график.
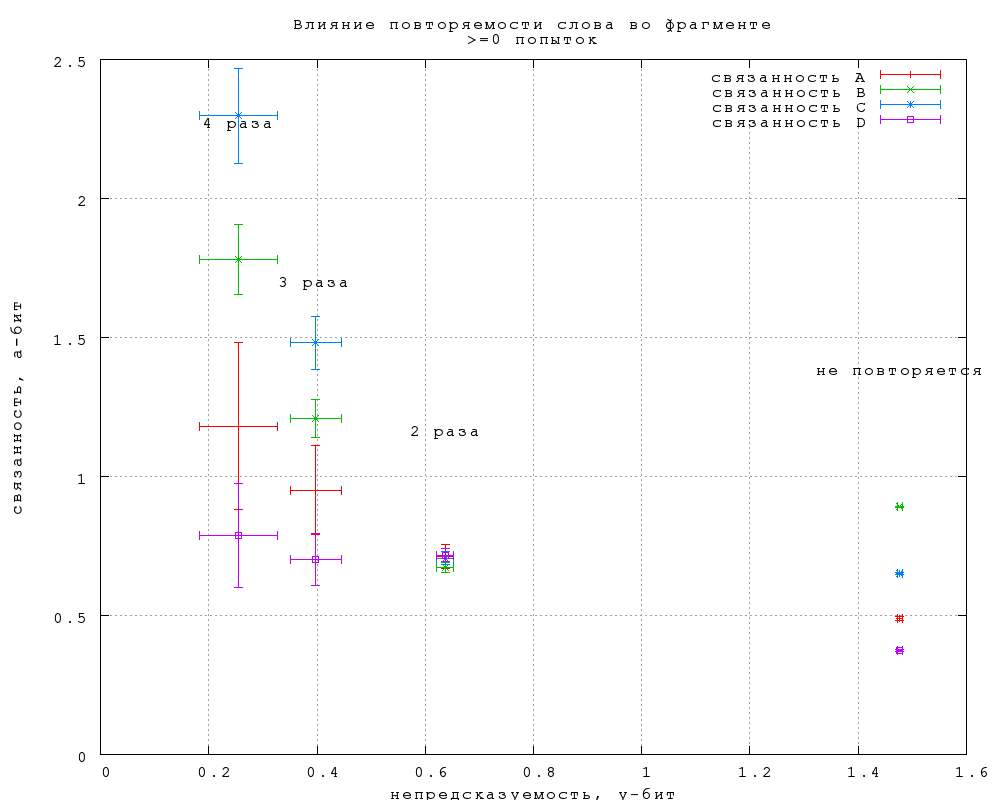
9. Влияние повторяемости слов
Повторяющиеся внутри фрагмента слова угадываются, очевидно,
легче. Менее очевидно, что на связанность любого типа повторение слова
влияния не оказывает. Согласно фиг. 27, различия в связанности
повторяющихся и неповторяюшихся слов не выходят за пределы
статистической погрешности, за исключением, может быть, троекратного
повторения ("То, что трижды сказал, то и есть" -- из "Охоты не Снарка"
в переводе Г. Кружкова). Заметим, что такое же отличие в поведении
непредсказуемости и связанности мы наблюдали по отношению к длине
слова.
10. Влияние стихотворного метра
На угадываемость слов в стихах, очевидно, оказывает большое влияние
стихотворный метр и ритм текста. В строго силлаботоническом
(достаточно, конечно, силлабичности) стихе число слогов (которое будем
называть для краткости "длиной" из-за двусмысленности термина
"сложность"), вообще говоря, строго задано. Однако в условиях нашего
эксперимента испытуемый должен самостоятельно делать вывод о строгости
или нестрогости метра конкретного текста по относительно небольшому
отрывку, и здесь возможны ошибки и неопределенности. К тому же, даже для
того, чтобы опознать и забраковать шестистопную строку только по
причине ее шестистопности в таком заведемо
пятистопном ямбе, как шекспировские сонеты, все равно требуется определенная
читательская квалификация. В результате около 1/7 всех неуспешных
попыток 1-го типа на шекспировских сонетах приводят к внеметрическим
заменам. И это учитывая только длину слова, но не ударение.
Чтобы добавить комментарий к любому предложению этого текста, щелкните мышью по точке, которой оно оканчивается